Note - 基础数据结构的一些简单操作
树状数组
树状数组是一个比较简洁且实用的数据结构。它可以在 的时间复杂度和 的空间复杂度(均为小常数)下支持单点修改和前缀询问的操作。在满足可减性的情况下,可以支持区间询问。
可以说树状数组是线段树的阉割版,但是它有着非常优秀的性能,代码实现难度也非常低。
详见树状数组。
线段树
简介
线段树是一个功能强大的数据结构,它的基本用途就是在单次操作 的时间内维护序列区间信息。它可以支持区间修改,区间查询(满足结合律的情况下)。
线段树是一棵二叉树。它的每个节点都代表了一个区间,其中根节点存放了整个序列的信息总和。每一个节点要么是叶子结点,要么有两个儿子。叶子结点代表了一个长度为 的区间,非叶子结点代表的区间是两个儿子节点代表区间的总和。
形象化地,一棵长度为 的线段树长这样:
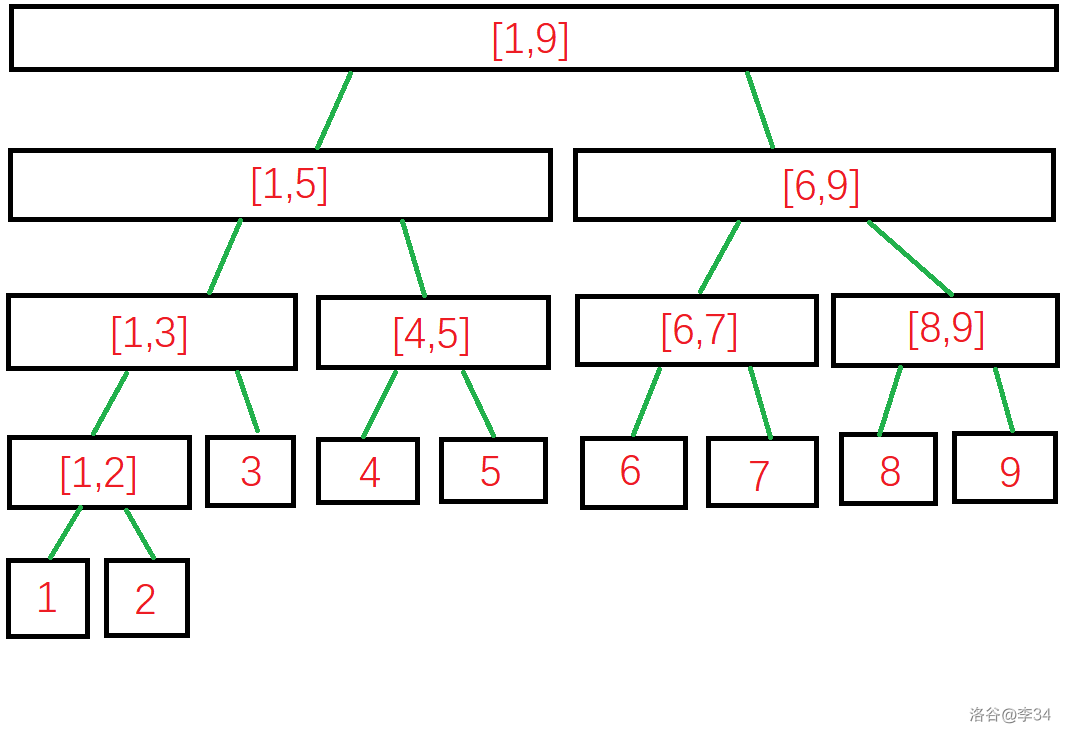
上图中每个黑框表示了一个节点,红色数字表示了每个节点代表的区间,绿线表示父子关系。
结构分析
从上图可以看出,每个节点的两个儿子尽可能均匀地划分了父亲代表的区间且刚好不重不漏,这保证了线段树的深度是 级别。
同时,这种方法的空间复杂度是 的。
值得注意的是,虽然在节点数量为 的整次幂时线段树刚好是一棵完美二叉树,在大部分情况下线段树会有一层不满的情况。
我们不难发现,线段树是一个递归的结构,所以我们在实现的时候常常使用递归的实现。
操作 1:单点修改,区间查询
先来看一道题:
问题 1:给定有 项的序列 。
现在有 次操作,每次操作是下面两种之一:
1.给定 ,将 加上为 。
2.给定 ,求出 。
。
显然可以用一个非常普通的数组维护这个操作。不过对于第二个操作,我们需要从 到 扫一遍,复杂度 ,太浪费时间了。我们当然可以使用树状数组解决这个问题,不过现在我们要学习的是线段树。为了做出这道题,我们需要考虑以下问题。
- 线段树的每一个节点需要维护什么信息?
很自然的想法就是让每个节点维护它所代表的区间的数之和。令 表示节点 所代表的区间的数之和。如果 是叶子结点,那么 就是它代表的数的值。如果 是非叶子节点,假设其左儿子为 ,右儿子为 ,很明显有 。
所以理论上只要我们知道了所有叶子结点的值,就可以知道整棵树的值了。于是我们可以递归地建树,初始化所有节点的信息。
我们假设原始序列为 ,则建出来的树长这样:
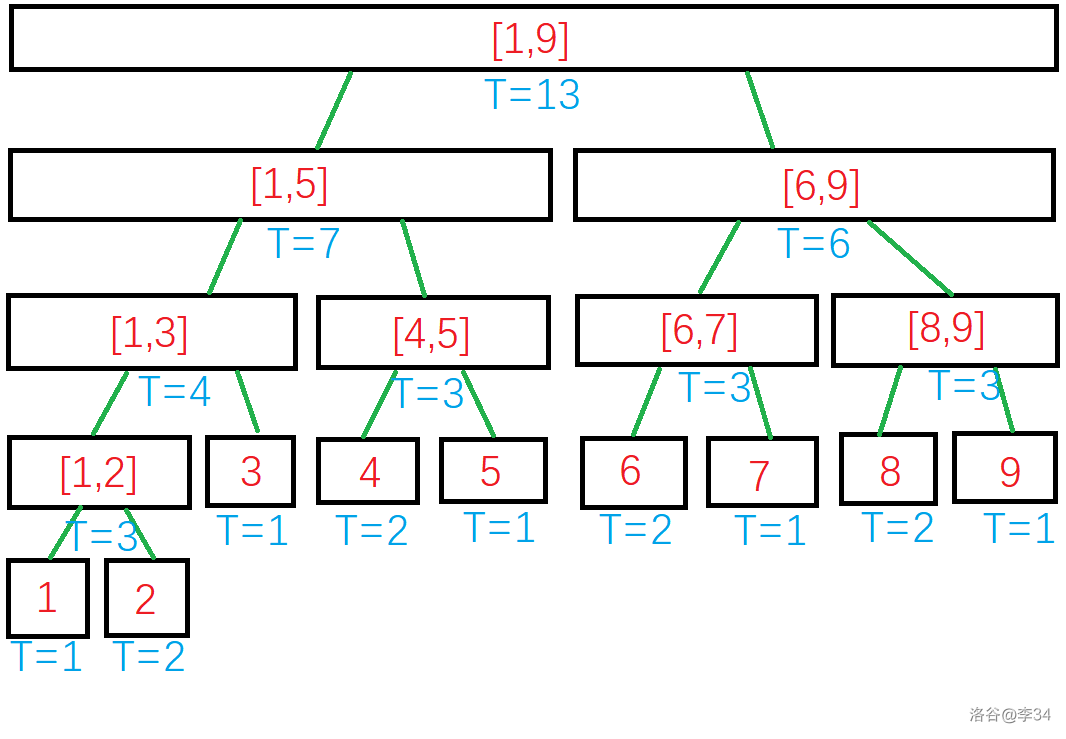
蓝色数字表示节点存放的信息。
- 如何进行操作 ?
每次要更新单点的信息时,只需要通过树边走到指定的叶子节点更新信息就好了。显然复杂度和树深度相同,是 的。
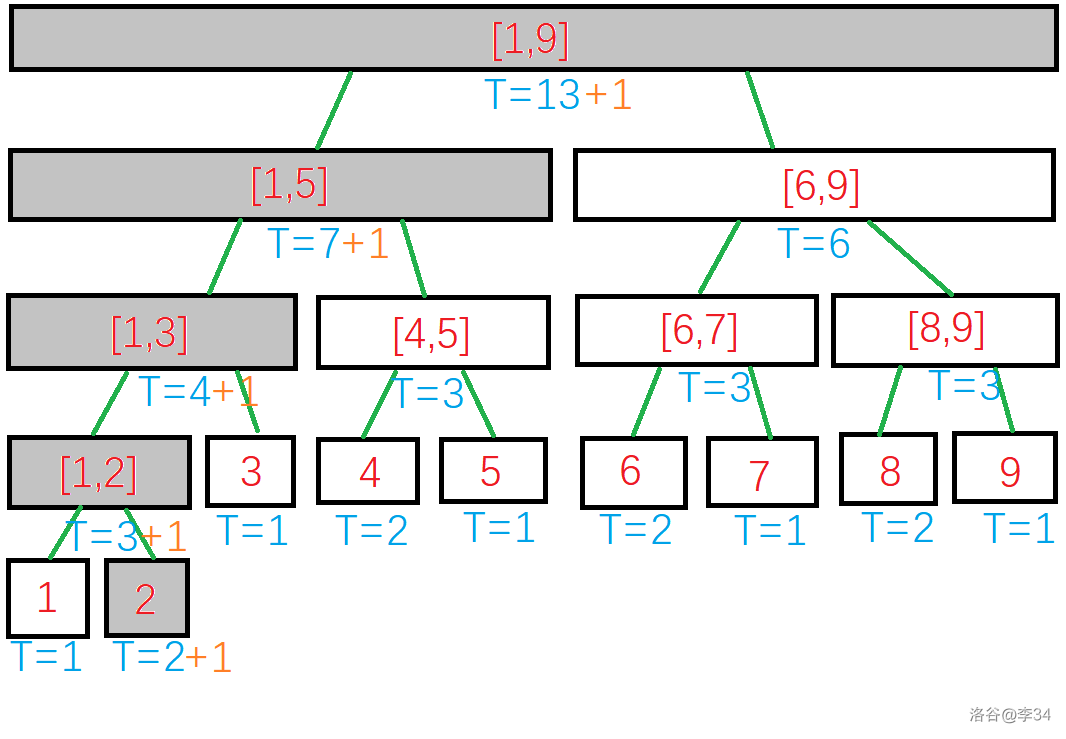
如何更新节点信息?对于叶子结点,直接更新。对于非叶子结点,运用之前的等式 就好了!因为只有途经的节点的信息会受到影响,所以我们只要在更新完叶子结点之后回溯时顺带更新即可。
如图,如果要让 加上 的话,灰色节点会发生改变,而白色节点不改变。
- 如何进行操作 ?
线段树建这么多层节点到底有什么用?在区间操作的时候我们就会发现它的方便之处了。
如果要查询的区间刚好是线段树上的一个区间,那好办,直接搜索到这个区间,然后返回值就好了。显然复杂度依然是 。
但更多情况下,查询的区间并不是线段树上完整的区间。这时,只需将该区间拆分成若干个线段树上的节点,再合并就行了。
比如说要查询 的话:
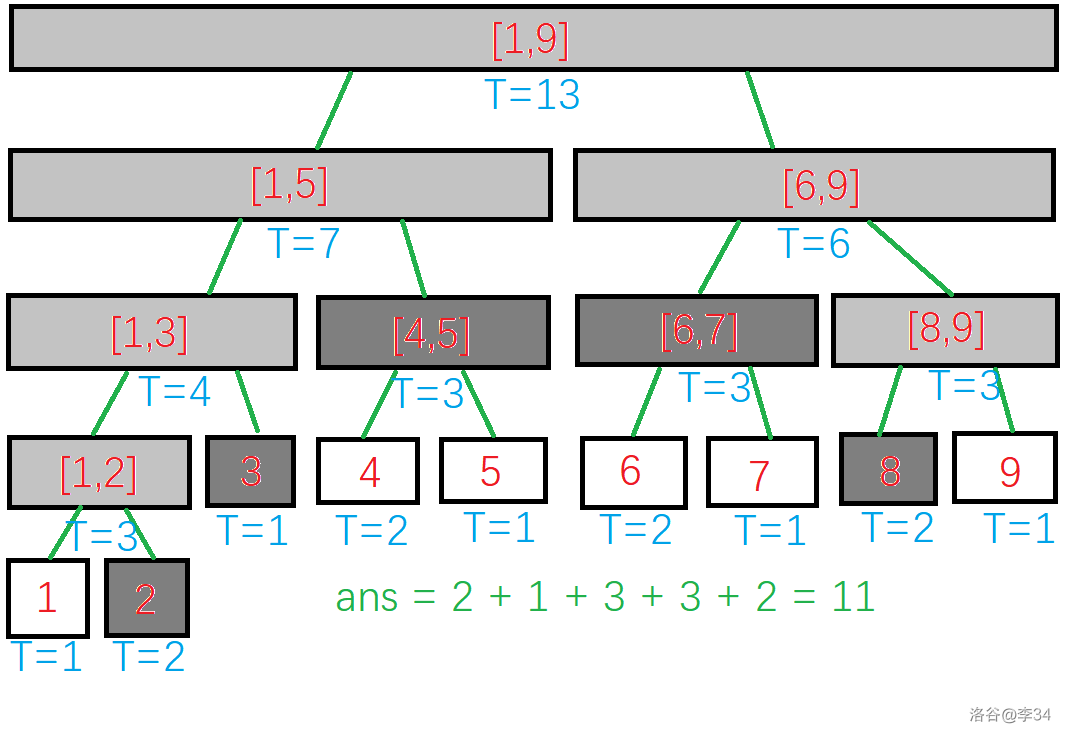
其中浅灰色节点表示途经而不加入计算的节点,深灰色节点表示加入计算的节点。
咋一看好像查询一次几乎覆盖了整棵树,复杂度会不会出问题呢?
但是,可以证明,单词查询复杂度依然是 的。
证明如下:
首先,定义加入计算(完全包含于查询区间且父亲不是完整节点)的节点为完整节点,定义在递归过程中(和查询区间有交集但不包含于查询区间)的节点为途经节点。
由于途经节点一定不包含于查询区间,又和查询区间有交集,故对于同一层的途经节点,一定只有一个或两个(即直接包含查询区间,或者一个跨过查询左端点、一个跨过查询右端点)。
那么完整节点的数量有多少呢?显然只有途经节点才会递归下去,那么最坏情况是这一层有两个途经节点,导致下一层有两个完整节点加上两个途经节点。换言之,由于每一层最多有两个途经节点,所以下一层最多只有四个节点,不管是完整节点还是新的途经节点。每层最多只会遍历四个节点,层数又是 的,所以节点总数为 。
这只是理论复杂度,实际上不需要考虑 这个常数,因为经常跑不满。
一些习惯记法
为了为后面的代码实现做准备,我们规定一些习惯。
-
表示 点的信息。
-
根节点为 ,节点 的左儿子是 ,右儿子是 。在程序中,可简写为
k<<1和k<<1|1。
这样节点会不会重复使用编号呢?不会的。如果我们考虑 的二进制表示,那么 相当于在它后面加了一个 , 相当于在它后面加了一个 。
注意,由于线段树有时不是完美二叉树,我们需要将空间开到序列大小的四倍!
- 区间 的两个儿子区间为 和 。其中 ( 表示 向下取整)。
这样可以保证区间尽可能均匀划分,又不会划分出空区间。
代码实现(问题 1)
现在来建树:
1 | const int N=1e5+5; |
根据我的习惯, 表示当前节点编号, 表示当前节点区间左端点, 表示当前节点区间右端点。
在读入完毕后,只需要在主函数里面 Build(1,1,n) 即可。时间复杂度 。
对于第一个操作,我们只需要将叶子结点的值改变之后,回溯时从下向上把途经的所有节点都 pushup 一遍就好啦。
1 | void Modify(int k,int l,int r,int pos,int v){ |
Modify(1,1,n,x,y) 可以把 加上 。
对于第二个操作,对于询问进行拆分,再相加即可。
1 | int Query(int k,int l,int r,int le,int ri){//查询区间[le,ri] |
Query(1,1,n,x,y) 可以求下标在 的数的和。
注意,只有修改了才需要 pushup ,查询时不需要。
这样一来,我们就在 的复杂度内解决了这道题。
懒标记
接下来是线段树的精髓:懒标记。这里只介绍标记下传法。
问题 2:给定有 项的序列 。
现在有 次操作,每次操作是下面两种之一:
1.给定 ,将 加上为 。
2.给定 ,求出 。
。
这个问题就是线段树 1。
显然,如果我们把区间内所有节点都修改一遍,那复杂度就变为了 ,不如暴力。
然而,根据区间查询的思想,我们不妨将修改的区间也拆分成线段树上的节点。这样的节点有 个。
但问题是,如果我们只更新这些节点,那当我们查询到这些节点子树内的节点时,就寄了。
但是我们发现,我们每次操作遍历的节点永远都只有 个。所以我们可以在修改一个区间时标记一下这个区间,当要用到此区间的子节点时,将标记传给子节点即可!这就是懒标记。一个节点 的懒标记记为 。
比如说我要将 增加 时,只需要将代表 的节点 ,即 ,增加 ,然后将 也增加 ,然后直接回溯。当我们再次走到 时,我们将 的 和 增加 ,将 的也都增加 就好了。这是标记下传的操作。
以下是代码实现。
1 | const int N=1e5+5; |
容易发现,总复杂度依然是 。
线段树实际上是较简洁的,而且思路清晰,不容易写错。
注意,以上代码不能通过线段树 1,因为要开 long long !
再补一些坑:<= 和 >= 写反;忘记 Build ;没初始化 lz ;没清空 lz ;区间加没有乘区间长;没 pushdown 。
有了懒标记,可以维护多种区间操作。如区间乘区间和,区间推平区间和,区间加区间max,单点修改区间最大子段和,甚至区间加区间sin和 。
在面对这些稀奇古怪的操作时,我们常常要对需要维护的式子变形。但线段树的基本框架并不会变,变的只是 pushup , pushdown , add 这些函数的写法而已。所以只要把板子敲熟练了,写错的几率不大。
线段树还可以同时维护多种操作。如区间加区间乘区间和,01序列区间赋0区间赋1区间取反区间和区间最长1串 。
还有一些特殊操作,比如区间开方区间和,区间排序最后单点询问。
当然,它也经常用于配合其他算法使用。
动态开点线段树
问题 3:有 项的序列 初始值全部为 。
现在有 次操作,每次操作是下面两种之一:
1.给定 ,将 加上为 。
2.给定 ,求出 。
。
显然,如果我们依然和以前一样建树的话,肯定会爆空间,因为序列实在是太长了。对此,我们可以使用离线离散化,把操作中的端点抽出来,然后再建树,这样复杂度可以做到 。然而如果我们懒得离散化,或者题目强制在线的话,就可以采用动态开点线段树。
现在我们假设还是和原来一样建树。由于每个操作只会遍历 个节点,所以实际上遍历用到的节点只有 个。也就是说,大部分的节点都是废物节点,完全用不着。这启示我们可以用一个点加一个点,从而节省空间。
既然要动态地开点,我们的左儿子和右儿子显然不能再是 和 了。我们得单独开一个数组来记录一下。记 的左右儿子分别为 。
代码实现的时候,我比较喜欢使用取地址的方式。注意,该方式可能不适用于 ,会出现不可预知的错误。建议预估空间开数组来存。
1 | const int N=1e5+5;//建树不需要了,因为初始都是0。 |
时间复杂度依然是 。
权值线段树
问题 4:有一个空序列,
现在有 次操作,每次操作是下面两种之一:
1.给定 ,在序列末尾加入 。
2.给定 ,求出 在序列中的排名(比 小的数的个数 )。
。
咋一看好像不是个线段树的题。写个平衡树或者直接全部丢到 里就完事了。但是我们想要使用线段树来完成这道题。
容易发现,序列中数的顺序没有用处,所以,以序列下标建树实为下策。而数之间的大小关系正是我们关心的。我们不妨转换一下思路——以数的值域建树,每个点存这个数出现的次数,也就是用线段树维护一个桶!这样一来,操作 就变成了 的和再 。这显然是可以通过线段树或者树状数组维护的。
值得一提的是,当 的值域比较大时,我们可以结合动态开点解决这个问题。
这种以值域建树的线段树被称为权值线段树,因为它的每一个点存的是这个数的权值。
问题 5:有一个空序列,
现在有 次操作,每次操作是下面两种之一:
1.给定 ,在序列末尾加入 。
2.给定 ,序列中第 小的数。
。
继续建立动态开点权值线段树。对于操作 ,可以用问题 查排名的方法结合二分来解决,但是这样会产生两个 ,感觉比较慢。
我们不妨直接在线段树上二分。当到达一个节点的时候,我们观察一下:如果左儿子里面存的数的个数大于等于 ,那么我们要找的数肯定在左边,就往左边走;否则肯定不在左边,那就往右边走。这样就可以做到一个 的查询啦!
结合问题 和问题 ,我们可以用比较简洁的代码切掉普通平衡树。
不过这个复杂度是 ,毕竟还是比平衡树的 要慢一些的(除了一些常数大的平衡树)。空间上也是 ,比较大。
线段树的合并与分裂
不想写
线段树的可持久化
不想写
平衡树
不想写。
树套树
分治
分治是一种思想。
首先是根号分治。
01Trie
分块
首先是序列分块。
顾名思义,序列分块就是将序列分成若干块,然后块内维护信息。当我们要进行查询时,只需要将序列中完整的块的信息全部加起来,然后再加上两端散点的信息即可。
设序列长度为 ,分成 块,则块的长度为 。区间查询时,整块部分的复杂度为 ,散点部分的复杂度为 。故总复杂度为 $O(m) + O(\frac{n}{m}) $ ,根据基本不等式,当 时最优。事实上,分块的效率很受常数的影响,所以调整块长是降低常数的常用方式。
从一种观点来看,线段树本质上就是递归的分块。线段树的查询可以保证区间能被拆分成若干个整块,而分块不能。所以分块仍然需要暴力的处理。
分块是整体处理和单点处理的平衡。通俗的说,和根号分治一样,就是两个暴力拼起来。它的效率低于线段树,但能实现很多线段树不能实现的功能。
块长并非取 最优,要视具体题目分析处理。